- Supertype
- Product & Services
- Portfolio
- Computer Vision
- Custom BI Development
- Managed Data Analytics & Development
- Programmatic Report Generation
Analytics Products & Services
Data analytics and data engineering services
Data Science by Applications
Implementations of data science in various industries
Bespoke solution for enterprises
Advisory & Consulting
Portfolio & highlights
Curation of featured projects and enterprise work
- Articles
Data Engineering
Technical articles by data engineers & automation developers solving real-world problems
Data Science
Articles and first hand observations by data scientists & analytics experts in the field
Full-Cycle Data Science Consultancy
Data Science & Analytics Consulting
- About
- Contact

Using Natural Language Processing (NLP) techniques and GloVe embeddings to study the keywords found on job descriptions online for a Data Analyst role
What makes a good Data Analyst candidate?
As a former business analyst I was used to thinking about our relationship with data and the role it plays in facilitating our decision making. Having completed my Masters degree in data and computational science last year, I am now making the transition into data science and analytics. In reviewing the various job descriptions of data analysts posted on LinkedIn, Indeed and Glassdoor I constantly find myself picking out keywords from the job summary; then, it occurs to me that this is a laborious process that can be automated through some form of natural language processing (NLP).
This article is a summary of that experiment.
Acquiring the Dataset
We will be using the dataset from Indeed (indeed.com). I start off by writing a simple scraper using the rvest library. To help illustrate this process, consider the following job posting for a Data Analyst position. Take note of the colored annotation 1 to 4 in the image below:
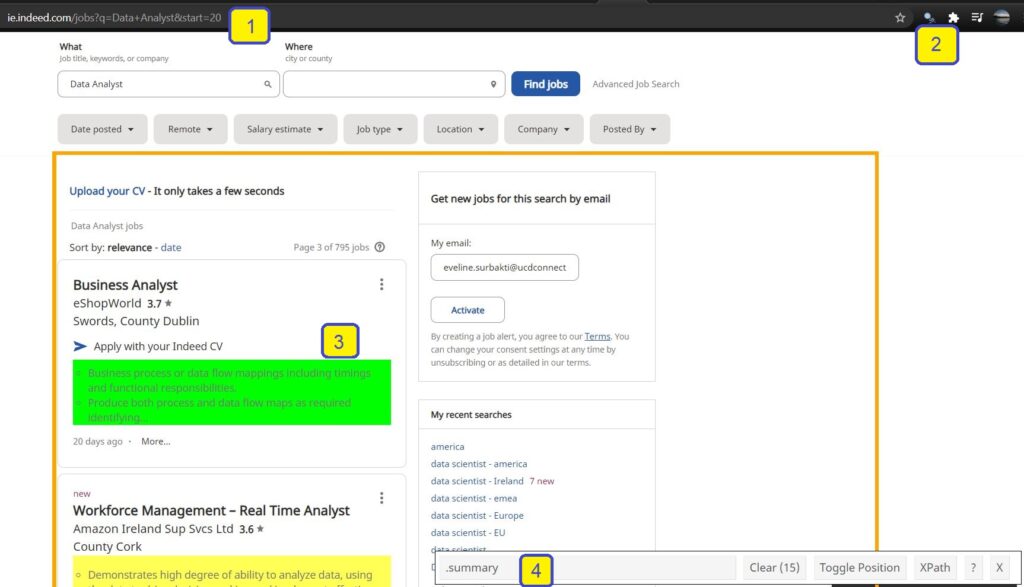
- The link to our target page; In this case, it’s a listing of all postings for the query “Data Analyst” found on the Ireland version of Indeed.com
- I use a simple Chrome extension to help retrieve the right css selector without too much hassle
- Select the area of the page
- Copy the css selector, in our case it is the “summary class” (
.summary)
So in short, our scraper follows the routine above to collect the information and store them into a DataFrame, filtered specifically for data analysts openings in Dublin, Ireland where I reside. I have also stored the years of experience required as a numeric value and done the necessary preprocessing that is typically involved in a language processing task:
- Removing stop words (words that have little value to our research objective)
- Remove punctuation, numbers, extra whitespaces
- Converting character strings into lowercases
Exploratory Data Analysis for Text
We begin with a basic but common NLP technique (“bag of words”) that constructs features based on terms / words (will be used interchangeably) frequencies. We use these features to train the classifier given a collection of text (also known as a corpus.)
Years of Experience for Data Analyst positions
The first question was “how many years of experience do employers require for their data analysts positions?” Because I scraped the website twice, once for all the openings in October and another for the following month, the distributions are plotted for each month:
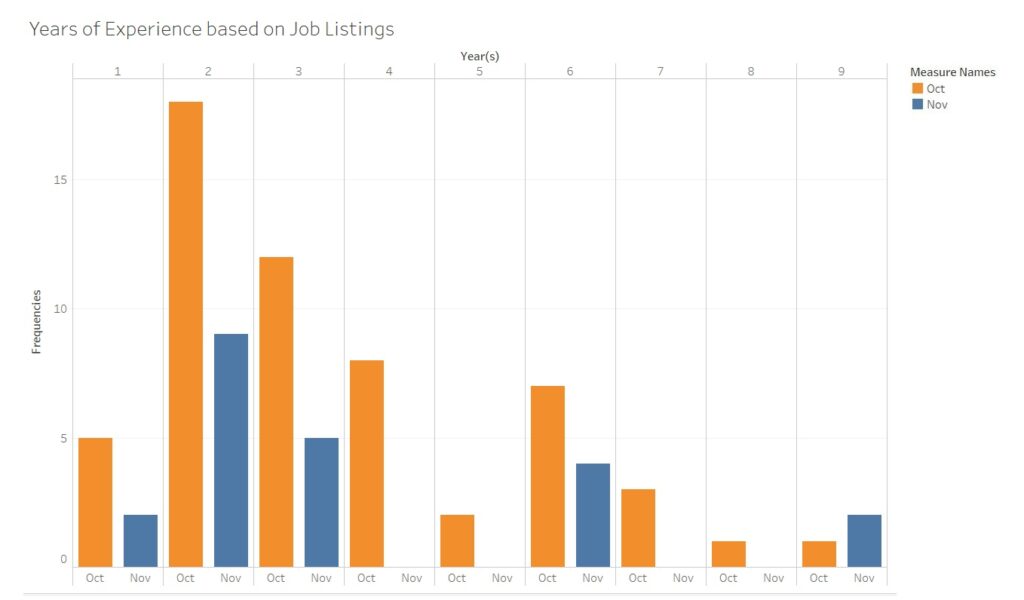
One can observe that most of the job openings for data analyst positions seek out for candidates with two to three years of experience.
Job listings to frequency tables
If we look at only the top 10 most frequent words from the November set, these are the top words by frequency (count):
Word n
data 909
experience 150
analyst 133
analysis 118
will 113
business 112
team 85
analysts 84
work 69
role 66 What’s interesting was that the word “experience” turns out to be the second most frequent, which underlines the emphasis that recruiters in placing when it comes to their candidates for the data analyst role.
We can also compute a frequency table for the recruiting companies. Based on what we scraped, the top 3 companies are recruitment agencies with a big presence in Ireland. These are the companies that are the most heavily represented for the word “data”:
Company Name Word n
Morgan McKinley data 36
Eolas Recruitment data 25
Accenture data 19
Regeneron data 19
Reperio Human Capital data 18
Eurofins Central Laboratory data 17
Segment data 15
TikTok quality 15
Red Tree Recruitment data 14
Red Tree Recruitment recruit 13 Words Visualization
We can also take a high level snapshot of word distributions. Unsurprisingly, the word “data”, “analyst”, as well as common functions relating to the job (“manage, experience, develop”, “process”, “compliance” etc) are the most common words in the job description for this role:

Unigrams and Bigrams
From the wordcloud visualization above, one could see how we sometimes fail to capture the full semantic of a phrase. “Data Management” or “Version Control” as a phrase means very different things when you split them up and consider the words as single terms (we call them “unigrams”). When we have a pair of consecutive terms, we call them “n-grams”. So a pair of two consecutive terms that make up a key phrase are called 2-grams, or bigrams.
These are a sample of unigrams and bigrams from our dataset (omitted the full result for brevity):
[1] "analysing" "drive" "sets"
[4] "trends" "analyst will" "data_analysts"
[7] "ensuring" "experienced" "maintain"
[10] "manager" "modelling" "operations"
[13] "privacy" "projects" "protection"
[16] "related" "solutions" "sources"
[19] "understand" "content" "data_quality"
[22] "development" "dublin" "product"
[25] "required" "business_analyst" "internal"
[28] "manage" "use" "data_integrity"
[31] "experience_data" "leading" "process"
[34] "teams" "test" "using"
[37] "based" "data_analyst" "system"
[40] "clients" "customer" "design"
[43] "insights" "market" "processes"
[46] "responsible" "security" "conduct"
[49] "join" "company" "global"
[52] "new" "requirements" "data_analytics"
[55] "provide" "reports" "within"
[58] "information" "looking" "technical"
[61] "compliance" "integrity" "key"
[64] "large" "risk" "tools"
[67] "years_experience" "complex" "identify"
[70] "analytics" "including" "sql"
[73] "knowledge" "review" "systems"
[76] "skills" "understanding" "financial"
[79] "ensure" "analytical" "reporting"
[82] "working" "ability" "years"
[85] "data_analysis" "management" "strong"
[88] "support"
...
[100] "data management" Similarity Analysis with GloVe Word Vectors
We can also find words that are most similar to the word “Business Analyst” or “Data Analyst” to help us a get a sense of topics or skills relating to our job-search. To compute similarity, I used Cosine distance and then perform the visualization of the top 10 words closest in vector space to “business analyst” or “data analyst”:
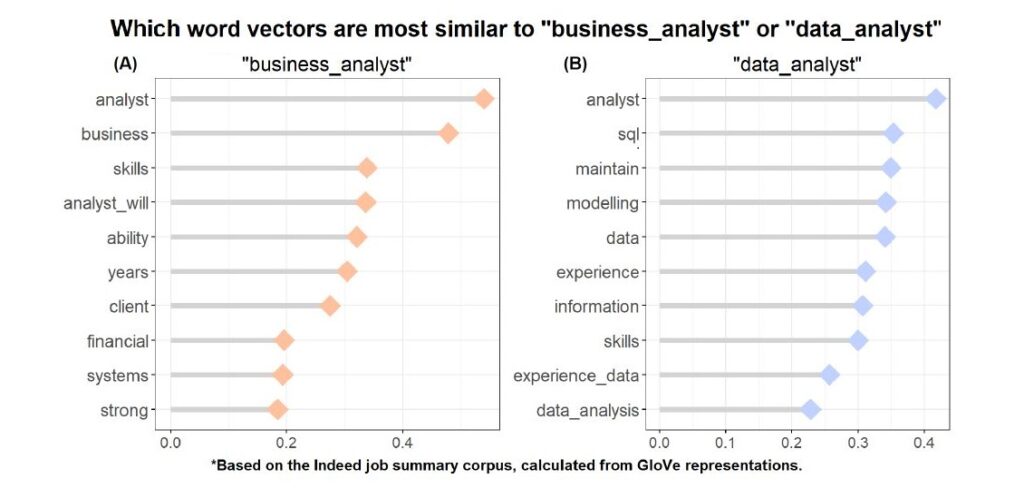
It seems that both of these jobs have a fairly high requirement for years of experience (“years”, and “experience” comes in on 6th and 5th place respectively), but they diverge in other areas: positions for business analysts use words such as “client”, “financial”, and “systems” while positions for data analysts have the closest terms as “data”, “modelling”, “sql” and “information”.
Plotting GloVe Word Vectors using Multidimensional Scaling
A vector with 100 dimensions would not be very helpful in terms of interpretation, so we will use MDS to produce a low dimensional representation of the data — while aiming to preserve the distances between points in the new representation. MDS essentially produces a ‘map’ of the observations onto new points that are in a lower dimensional space.
Once we’ve applied MDS with Euclidean distances between these word vectors, we can visualize them and use this new representation to uncover groupings of words into broader subject areas.

I expected terms close to each other in this reduced vector space to be semantically similar, meaning they are commonly found within the same context and are transposable within the corpus. There are some clear and evident trend from the figures: The terms seem to be stratified primarily by frequency.
Where:
- Higher frequency terms are more separated and isolated. These terms be placed within the multidimensional space in a location that depicts its distinct meaning.
- Low frequency terms tend to aggregate around each other, often overlapping to show how close they are. These terms cannot be determined as precisely, so their encodings tended to settle closely to each other without much differentiation. Sometimes we ‘could not’ find them.
Here are a summary of my top findings from our study of most common phrases in the job openings for data analysts (bold emphasis are keywords resulting from the earlier exercise):
- business and business related analysis are important for an data analyst, (sometimes) as a driver of business, a data analyst should have business acumen and ability to derive value for the business
- years, experience and years_experience are vital in job description of a data analyst, highlighting the emphasis on employment history and experience
- SQL is important
- Also important is data treatment, ranging from security (privacy and security), to protection, integrity and compliance
- Understanding the requirement is another important aspect of the job for any budding data analyst.
- Data analyst should be able to handle complex and large data set.
- Knowledge and throughly understanding about operation and process of a business (relating to the first point)
- Teamwork is important, as analysts often plays a supportive role and are expected to work in teams